Bau dir deinen eigenen SEO Crawler
Wir standen vor einer simplen Aufgabe mit unbequemen Details: einen Onlineshop mit rund 15.000 Seiten komplett auditieren. Nicht nur Titles und Meta Descriptions, sondern auch strukturierte Daten, H1 Hygiene, dünne Kategorietexte und die Frage, wie gut die Seiten für AI Search und LLM Antworten aufgestellt sind. Und das idealerweise wiederholbar, jeden Monat, ohne jedes Mal von vorne anzufangen.
Man kann dafür ein fertiges Tool mieten. Wir haben uns entschieden, unseren eigenen Crawler zu bauen. Dieser Artikel ist das ehrliche Protokoll davon. Mit den Entscheidungen, mit der Wand, gegen die wir gelaufen sind, und mit dem Trick, der sie eingerissen hat.
Kurz gesagt: Ein eigener SEO Crawler ist heute erstaunlich wenig Code. Die harte Nuss ist nicht das Parsen von HTML, sondern zwei Dinge: nicht von der Schutzschicht des Shops ausgesperrt zu werden und einen Abbruch bei 15.000 Seiten unbeschadet zu überstehen. Beides haben wir gelöst.
Was euch in diesem Artikel erwartet
- Warum überhaupt selbst bauen und wann sich das lohnt
- Die Tech Entscheidung, mit der aus der Idee an einem Nachmittag ein Werkzeug wird
- Die Architektur, Schritt für Schritt, mit echten Code Auszügen
- Die Wand aus 429ern, unser ehrlichster Moment
- Der Durchbruch mit Web Bot Auth und die Zahlen davor und danach
- Resumierbarkeit in echt, damit ein Timeout nichts kostet
- Was am Ende dabei herauskommt und was wir damit im SEO anfangen
Warum überhaupt selbst bauen
Fertige Crawler sind stark. Aber wir wollten drei Dinge, die uns wichtiger waren als Bequemlichkeit:
Genau unsere Felder. Wir wollten pro Seite nicht nur die Klassiker, sondern auch die Typen der JSON LD Schemata, die Indexierbarkeit mitsamt Grund und ein Gefühl dafür, wie zitierfähig eine Seite für AI Antworten ist. Wer die Datenerfassung selbst schreibt, bekommt exakt die Spalten, mit denen später die Arbeit leichter wird.
Volle Kontrolle über den Ablauf. Wie wird normalisiert, was wird ausgeschlossen, wie höflich wird gecrawlt, wie geht es nach einem Abbruch weiter. Bei 15.000 Seiten sind das keine Randnotizen, sondern der Unterschied zwischen sauberen Daten und Datenmüll.
Nahtlose Integration. Das Ergebnis soll direkt in unsere weiteren Werkzeuge fließen, in Reports, in Google Docs, in die nächste Analyse. Ein eigenes Tool ist genau so integrierbar, wie wir es brauchen.
Der ehrliche Zusatz: Es macht Spaß, und man versteht danach jede Zahl im Report, weil man weiß, wie sie entstanden ist.
Die Tech Entscheidung
Wir haben uns bewusst für einen kleinen, langweiligen Stack entschieden. Langweilig ist bei Werkzeugen ein Kompliment.
| Baustein | Wahl | Warum |
|---|---|---|
| Laufzeit | Node | natives fetch, schnelle Nebenläufigkeit, kein Ballast |
| Speicher | node:sqlite |
in Node eingebaut, kein externer Dienst, macht den Crawler resumierbar |
| HTML | cheerio | robustes Parsen wie mit jQuery, battle tested |
Der wichtigste Punkt ist die eingebaute SQLite. Sie ist nicht nur Ergebnisspeicher, sondern auch die Warteschlange. Genau das macht den Crawler von Anfang an unterbrechungssicher. Dazu gleich mehr.
Die Architektur
Warteschlange und Ergebnisse in einer Tabelle
Es gibt eine Tabelle urls. Jede URL ist genau einmal enthalten, die URL selbst ist der Primärschlüssel. Das erledigt die Duplikatserkennung geschenkt: Eine schon bekannte URL ein zweites Mal einzutragen, wird von der Datenbank einfach ignoriert.
INSERT OR IGNORE INTO urls (url, state, depth, discovered_from)
VALUES (?, 'queued', ?, ?)
Jede Zeile hat einen Zustand: queued, processing, done, error oder skipped. Der Crawler zieht sich immer den nächsten Schwung queued Zeilen, arbeitet sie ab und schreibt das Ergebnis in dieselbe Zeile zurück. Die Warteschlange lebt also in der Datenbank, nicht im Arbeitsspeicher. Das ist der Schlüssel für alles, was später kommt.
Der Crawl Loop mit Nebenläufigkeit
Der Ablauf ist ein klassischer Breitensuchlauf. Hol dir den nächsten Batch, verarbeite ihn mit einer festen Zahl paralleler Arbeiter, wiederhole, bis die Warteschlange leer ist.
while (true) {
const batch = naechsteQueuedUrls(concurrency * 4)
if (!batch.length) break // Warteschlange leer, fertig
await runPool(batch) // parallel abarbeiten
}
Die Nebenläufigkeit ist bewusst begrenzt. Nicht weil der Rechner nicht mehr könnte, sondern weil der Shop nicht mehr mag. Das ist der eigentliche Knackpunkt eines Crawlers und der Grund für den dramatischsten Teil dieser Geschichte.
URLs normalisieren, sonst explodiert alles
Ohne saubere Normalisierung crawlt man denselben Inhalt hundertfach. Wir werfen Anker weg, entfernen Tracking Parameter wie utm_ oder gclid, sortieren die restlichen Parameter und lassen offensichtliche Nicht Seiten wie Bilder, Skripte oder PDFs gar nicht erst in die Warteschlange. Optional lässt sich der komplette Query String ignorieren, was bei Shops mit vielen Filtern Gold wert ist.
Was pro Seite erfasst wird
Für jede URL landet ein voller Datensatz in der Tabelle, in der Art, wie man es von den großen Tools kennt:
Status, Weiterleitungsziel, Antwortzeit, HTML Größe und Tiefe. Title und Meta Description samt Länge. Meta Robots und der X Robots Tag aus dem Header. Canonical inklusive der Frage, ob sie auf sich selbst zeigt. Daraus die Indexierbarkeit mit Begründung. Alle H1, die Zahl der H1 und H2, die Wortzahl. Die Typen der JSON LD Schemata. Open Graph, hreflang, Bilder gesamt und Bilder ohne Alt Text sowie interne und externe Links.
Die Indexierbarkeit ist dabei kein simples Ja oder Nein, sondern kommt mit Grund: noindex, canonicalised, redirect, non-200 oder eben indexable. Genau diese Begründung spart im Audit später Stunden.
Der ehrlichste Teil: die Wand aus 429ern
Der erste Lauf gegen den echten Shop fühlte sich großartig an. Rund 20 Seiten pro Sekunde, Daten liefen sauber ein. Und dann kippte es. Nach den ersten knapp 50 Seiten kam Status um Status dasselbe zurück: 429 Too Many Requests. Von 200 Anfragen waren am Ende 149 abgeblockt. Kurz darauf war sogar die simple Startseite nicht mehr erreichbar, ebenfalls 429, minutenlang.
Was war passiert. Jeder ernsthafte Shop sitzt hinter einer Schutzschicht, in diesem Fall Cloudflare. Die unterscheidet menschlichen Verkehr von automatischem und drosselt automatischen hart, sobald er zu schnell wird. Aus Sicht der Schutzschicht sah unser Crawler nach einem kleinen Ansturm aus. Die Antwort war eine Sperre, und die galt für unsere IP für eine ganze Weile.
Das ist keine Schwäche des Crawlers. Das ist genau die Wand, gegen die auch die bekannten Desktop Tools laufen. Wichtig war die Lehre daraus: Geschwindigkeit ist nicht das Ziel, saubere und vollständige Daten sind das Ziel.
Höflichkeit als Pflicht: adaptives Backoff
Der erste Fix war, dem Crawler Manieren beizubringen. Trifft eine Anfrage auf 429 oder 503, dann wartet der Crawler, statt stur weiterzufeuern. Er respektiert den Retry-After Header, wenn der Server einen schickt, und legt sonst eine exponentiell wachsende Pause ein. Und zwar nicht nur für die eine Anfrage, sondern als globale Bremse für alle Arbeiter gleichzeitig, damit nicht sieben andere munter weiterlaufen, während einer schon abgewiesen wurde.
if (status === 429 || status === 503) {
const wait = retryAfter ?? backoff // Server bittet, oder wir schätzen
globalPauseUntil = Date.now() + wait // alle Arbeiter warten mit
await sleep(wait)
backoff = Math.min(backoff * 2, 30000) // beim nächsten Mal länger
}
Damit lief der Crawl wieder, aber langsam. Höflich und langsam ist besser als schnell und gesperrt. Trotzdem wollten wir mehr, denn es ging um unseren eigenen Kundenshop, den wir mit vollem Recht auditieren.
Der Durchbruch: Web Bot Auth
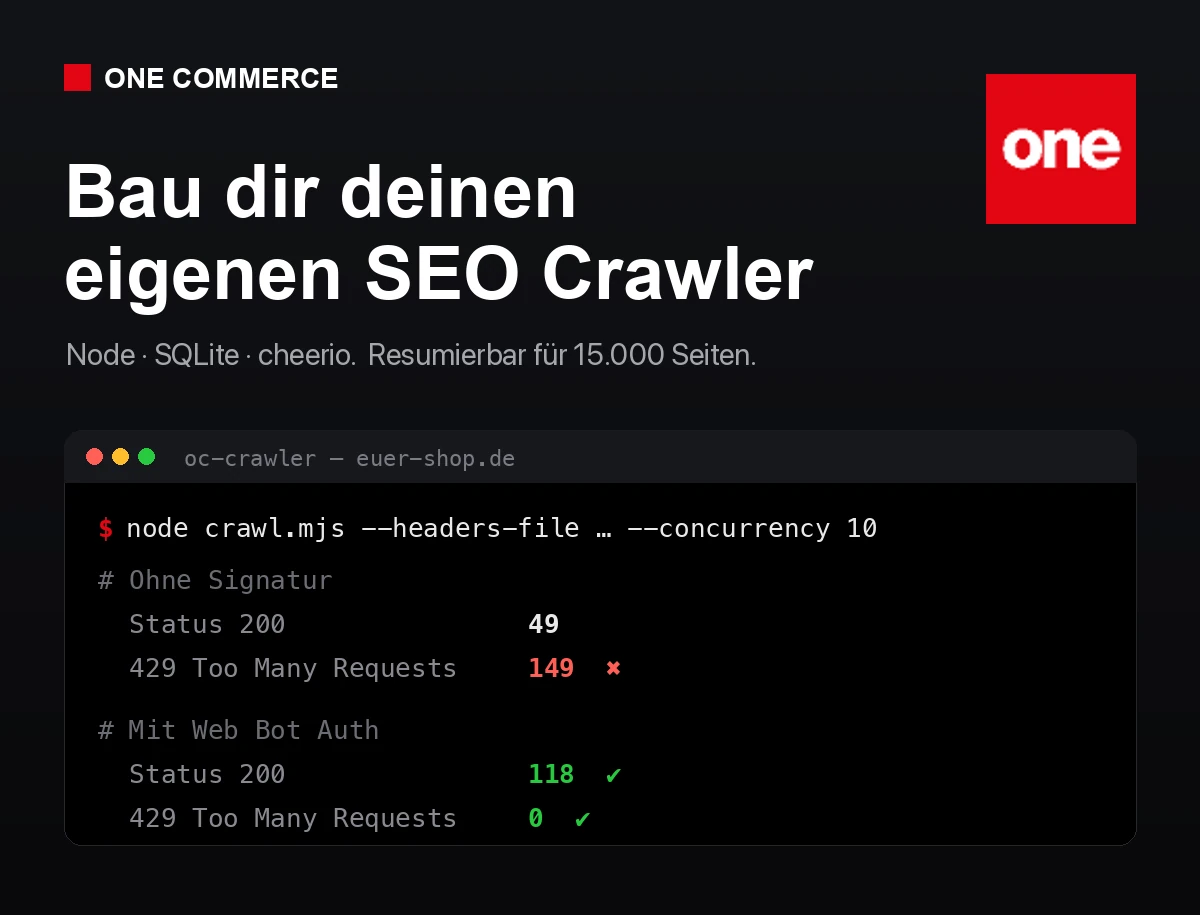
Die saubere Lösung kommt von Shopify selbst und heißt Web Bot Auth. Der Crawler weist sich damit kryptografisch aus, signiert seine Anfragen, und die Schutzschicht erkennt ihn als autorisiert und lässt ihn mit deutlich höheren Limits durch. Man erstellt die Signatur im Shop Admin mit wenigen Klicks, kopiert drei Header und schickt sie bei jedem Request mit. Den ganzen kryptografischen Teil übernimmt Shopify. Die komplette Anleitung dazu haben wir in einem eigenen Artikel Schritt für Schritt aufgeschrieben: Full Speed Crawl ohne 429er in Shopify.
In unseren Crawler war das schnell integriert. Die drei Werte liegen in einer separaten Datei, die niemals ins Repository wandert, und werden bei jedem Request als zusätzliche Header mitgeschickt.
node crawl.mjs https://www.euer-shop.de \
--headers-file webbotauth.euer-shop.headers --concurrency 10
Der Unterschied war sofort messbar. Derselbe Lauf, dieselbe Geschwindigkeit, einmal ohne und einmal mit Signatur:
# Ohne Signatur, volle Geschwindigkeit
200 OK: 49
429: 149 ← Wand aus 429ern, danach IP fuer Stunden gesperrt
# Mit Web Bot Auth, gleiche Geschwindigkeit
200 OK: 118
429: 0 ← sauber durch, kein Stau, kein Ban
Aus einer Wand wurde eine offene Tür. Signierter Verkehr ist gewollter Verkehr.
Resumierbarkeit in echt
Bei 15.000 Seiten ist die Frage nicht ob, sondern wann ein Lauf unterbrochen wird. Ein Timeout, ein Neustart, ein kurzer Netzhänger. Weil Warteschlange und Ergebnisse in der SQLite Datei liegen, ist das kein Drama. Ein erneuter Start setzt genau dort fort, wo aufgehört wurde.
Eine Kleinigkeit hat uns das im Test gelehrt. Wird ein Lauf mitten in einem Batch abgeschossen, bleiben ein paar URLs im Zustand processing hängen und würden beim Fortsetzen übersprungen. Der Fix ist eine einzige Zeile beim Start, und der Crawl ist wirklich unterbrechungssicher:
UPDATE urls SET state = 'queued' WHERE state = 'processing'
Genau solche Details trennen ein Skript von einem Werkzeug.
Was am Ende dabei herauskommt
Am Ende steht eine CSV mit einer Zeile pro Seite und allen oben genannten Feldern, dazu eine kurze Zusammenfassung direkt im Terminal: wie viele Seiten mit Status 200, wie viele Weiterleitungen, wie viele ohne Title, ohne Meta Description, ohne H1, ohne Schema, wie viele dünn.
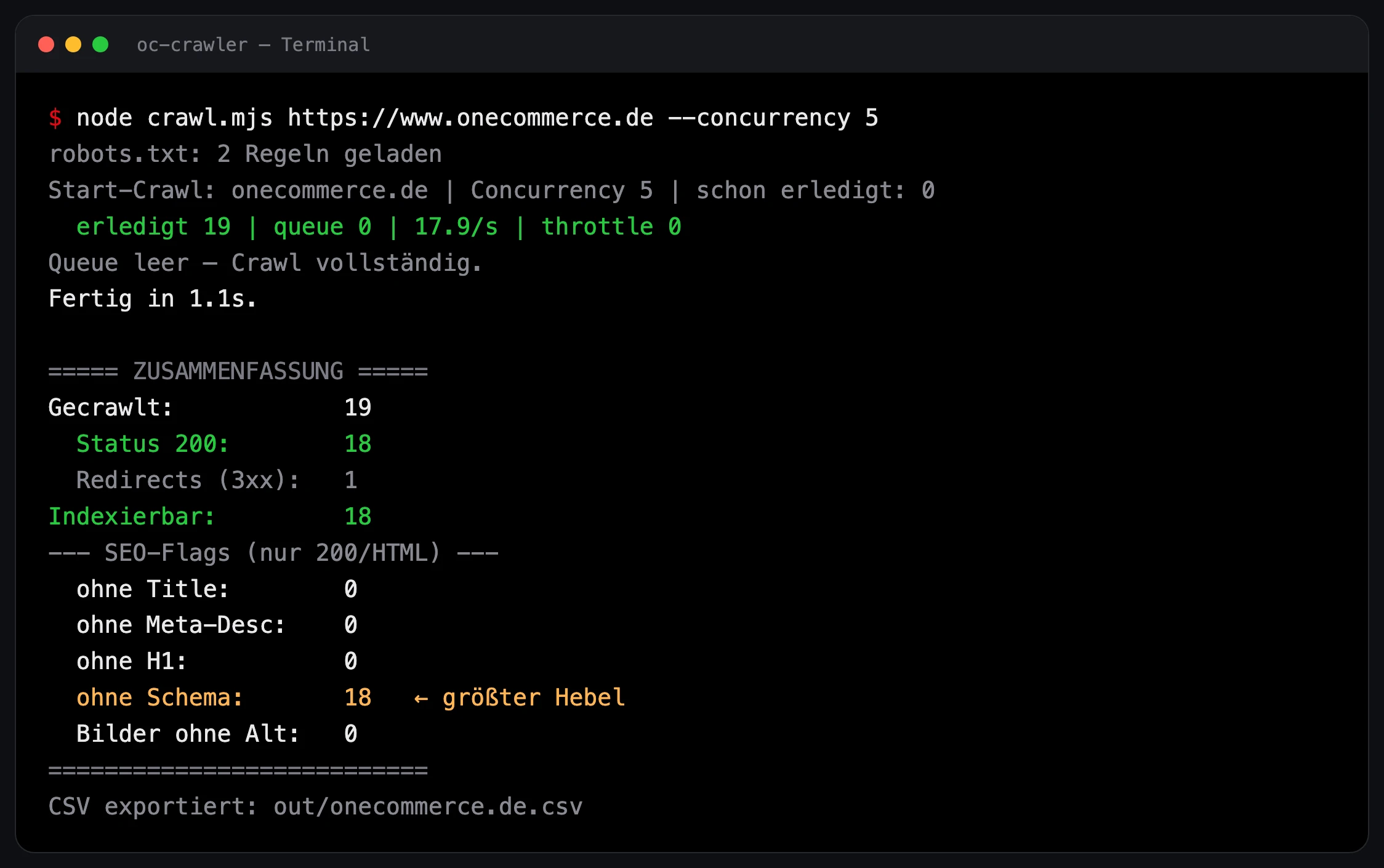 Die Zusammenfassung direkt im Terminal, hier ein sauberer Lauf gegen unsere eigene Seite. Der größte Hebel springt sofort ins Auge: keine Seite mit strukturierten Daten.
Die Zusammenfassung direkt im Terminal, hier ein sauberer Lauf gegen unsere eigene Seite. Der größte Hebel springt sofort ins Auge: keine Seite mit strukturierten Daten.
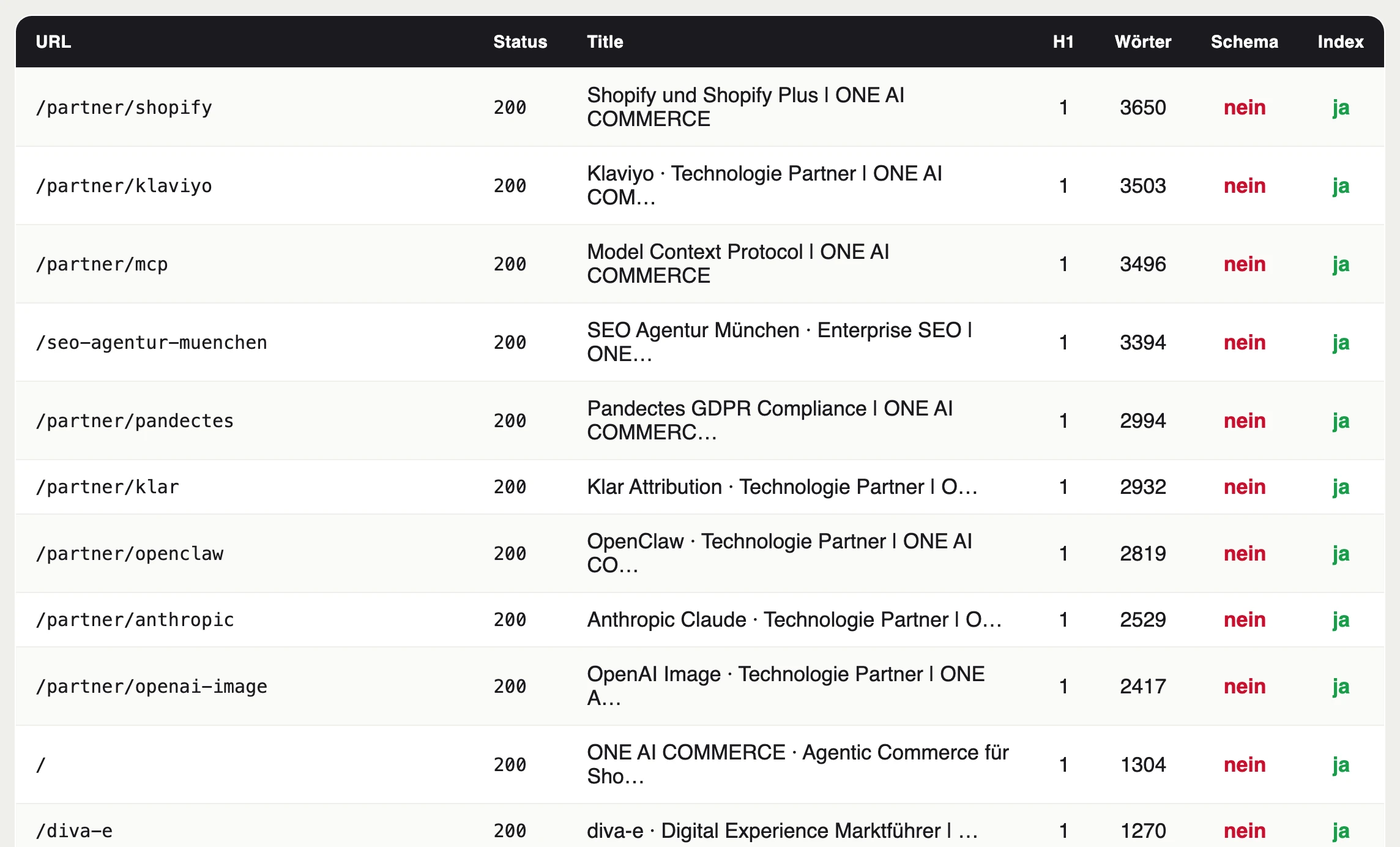 Ein Ausschnitt aus der CSV. Jede Zeile eine Seite, mit genau den Feldern, die im Audit zählen. Die Spalte Schema zeigt hier durchgehend nein, genau so findet man den größten Hebel in Sekunden.
Ein Ausschnitt aus der CSV. Jede Zeile eine Seite, mit genau den Feldern, die im Audit zählen. Die Spalte Schema zeigt hier durchgehend nein, genau so findet man den größten Hebel in Sekunden.
Und genau da wird es für SEO spannend. Der erste vollständige Lauf zeigte auf einen Blick die großen Hebel. Keine einzige der wichtigen Seiten hatte strukturierte Daten. Auf Top Seiten mit viel Traffic fehlte die H1 oder sie kam mehrfach vor. Viele Kategorietexte waren zu dünn, um sowohl bei Google als auch in AI Antworten zu bestehen. Das sind keine Vermutungen mehr, das sind gezählte Fakten aus der eigenen Datenbank.
Die Lektionen
- Das HTML Parsen ist der einfache Teil. Die echten Probleme sind Rate Limiting und Wiederaufnahme.
- Höflichkeit ist keine Option. Ein Crawler ohne Backoff sperrt sich selbst aus und schadet dem Shop.
- Für den eigenen Shop gibt es den offiziellen Weg. Web Bot Auth macht aus Schneckentempo vollen Speed, sauber und erlaubt.
- Zustand gehört auf die Platte, nicht in den Arbeitsspeicher. Dann ist jeder Abbruch nur eine Pause.
- Baue die Felder, die du wirklich auswertest. Ein Crawler, der Schema Typen und Indexierbarkeit mitliefert, spart im Audit die meiste Zeit.
Fazit
Ein eigener SEO Crawler ist kein Monatsprojekt. Er ist ein überschaubares Werkzeug, das man an einem fokussierten Tag zum Laufen bringt und danach immer weiter schärft. Der Gewinn ist doppelt: Man bekommt exakt die Daten, die man für gutes SEO und für AI Sichtbarkeit braucht, und man versteht jede Zahl im Report, weil man weiß, wie sie entstanden ist.
Muss das jeder selbst bauen. Nein. Aber wenn ihr regelmäßig große Shops auditiert und die volle Kontrolle über Datenqualität und Ablauf wollt, dann lohnt es sich. Und der Weg dahin ist kürzer, als die meisten denken.
Wollt ihr, dass wir euren Shop mit genau diesem Werkzeug einmal komplett durchleuchten. Meldet euch bei ONE COMMERCE, wir zeigen euch, was in euren Seiten steckt.